


constexpr:编译期求值的秘密
constexpr 是 C++11 引入的关键字,表示一个表达式或函数可以在 编译期求值。 constexpr 修饰变量编译期计算值。constexpr 本身不是类型限定符,但它对变量 隐含顶层 const。 举例说明: 1constexpr int* ptr = &val; ptr 本身不可变(不能指向别的地址)。 但可以通过 ptr 修改 val 的值(*ptr = 10; 是合法的)。 constexpr 修饰函数告诉编译器: “如果参数都是编译期常量,编译的时候就把结果算出来;如果不是,就把它当作普通函数在运行期执行。” 为什么要使用 constexpr?把运行时的计算提前到了编译期,减少了运行时开销。 如何实现编译时计算?这是 constexpr 的核心,也是一直困扰我的问题。 我困扰的点是:AST 解释执行 这个东西除了教学以外还有什么应用场景? 之前在写 Pinky 编译器 的时候,第一个实现的执行方式就是遍历 AST 执行,但我一直很难想到这种执行方式的其他实际应用场景。今天突然想到 constexpr,来看了一下它的实现,终于明白了它的使...
Virtually Indexed, Physically Tagged (VIPT)
VIPT (Virtually Indexed, Physically Tagged) 是一种在 L1 Cache 上的主流设计。它将内存寻址中的部分操作由串行改为并行,从而大幅缩短了从 Cache 获取数据的时间。 内存访问的核心组件在 CPU 执行 Load/Store 指令进行内存读写时,主要涉及两个核心组件:LSU 和 MMU。 LSU (Load Store Unit):位于 CPU 流水线的后端,专门负责处理所有的加载(Load)和存储(Store)指令。 MMU (Memory Management Unit):内存管理单元,负责虚拟地址到物理地址的转换。 VIPT 的工作流程使用 VIPT 后,Load/Store 指令查找物理地址的流程如下: LSU 拿到一条指令并计算出目标 虚拟地址 后,会 并行 进行以下两个操作: MMU 查物理地址 (TLB Lookup): LSU 将虚拟地址发给 MMU。 MMU 首先在 TLB (Translation Lookaside Buffer) 中寻找对应的 VPN (Virtual Page...

Single Instruction, Multiple Data (SIMD)
本文为学习 Computer Enhance - Single Instruction, Multiple Data 的整理。 回顾与引入在前一篇博客中,我们通过 打破指令依赖链,让 CPU 可以并行执行 add 操作,从而提升了性能。 在这篇博客中,我们回到第一种优化方式:通过使用 SIMD 指令来减少指令总数。 SIMD 全称 Single Instruction, Multiple Data(单指令多数据),它的意思正如字面所示:CPU 用一条指令同时处理多份数据。 SIMD 基础常见的 SIMD 指令集包括 SSE、AVX 和 AVX-512。指令宽度依次加倍,分别是 128 bit、256 bit 和 512 bit。宽度决定了一条指令一次性可以计算的数据长度。 现在的家用电脑一般都支持到 AVX2。下图是我的 CPU 数据,可以看到对 SIMD 指令集的支持情况: 寄存器对应关系SIMD 指令会使用专用的寄存器做计算: SSE (128位): 使用 XMM0 ~ XMM15 AVX (256位): 使用 YMM0 ~ YMM15 XMM0 是 YMM0 的低 1...

Break the Serial Dependency Chain
本文为学习 Computer Enhance - Instructions Per Clock 的整理。 前情回顾上一篇博客中,我们通过循环展开进行了示例代码的优化,也遇到了串行依赖链的问题。这篇博客就来进一步说明。 之前的优化代码: 123456789101112u32 Unroll4Scalar(u32 Count, u32 *Input){ u32 Sum = 0; for (u32 Index = 0; Index < Count; Index += 4) { Sum += Input[Index]; Sum += Input[Index + 1]; Sum += Input[Index + 2]; Sum += Input[Index + 3]; } return Sum;} 什么是串行依赖链?每个 add 的第一个操作数始终是同一个累加值 Sum。它既是 add 的源,也是其目的地。 这部分代码是一个 串行依赖链:整个求和过程中的每一...

Unrolling a Loop
本文为学习 Computer Enhance - Instructions Per Clock 的整理。 问题引入有如下代码: 1234567891011typedef unsigned int u32;u32 SingleScalar(u32 Count, u32 *Input){ u32 Sum = 0; for (u32 Index = 0; Index < Count; ++Index) { Sum += Input[Index]; } return Sum;} 每颗 CPU 在理论上每个时钟周期都能执行一定数量的指令,而我们的工作负载越接近这个数量,就越能发挥这颗 CPU 的全部潜力。 上述代码中,可以认为 加法是工作负载,而 循环是一种”浪费”。下面是上述代码生成的汇编: 1234567891011121314151617SingleScalar: test ecx, ecx ; if (Count == 0) je ....

Waste
本文为学习 Computer Enhance - Waste 的整理。 核心观点提升程序性能只有两条路: 减少要求 CPU 执行的指令总数 调整这些指令,让它们更高效地穿过 CPU 除此之外,别无他法:要么减少数量,要么加快速度。 CPU 正在执行的指令中,存在大量指令,它们所做的事情,与实际程序逻辑毫无关系。 案例:计算 A + B运行在两个较为极端的环境下: C 语言:编译为原生机器码,运行在 CPU 上 Python:编译为字节码,运行在 CPython 虚拟机上(没有 JIT) C 语言实现测试代码: 12345678910int __declspec(noinline) add(int A, int B){ return A + B;}#pragma optimize("", off)int main(int ArgCount, char **Args){ return add(1234, 5678);} 可以看到为了实现 A + B,只使用了 一条 ADD 指令。 Python ...
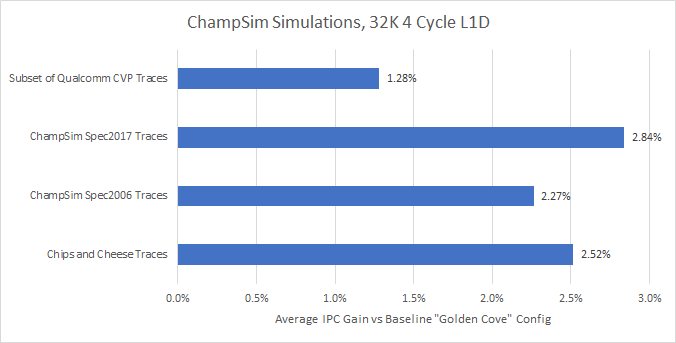
Cache
DRAM 读取速度太慢,所以就有了缓存。但同时也引入了缓存抖动、伪共享、读后写、一致性等需要解决的问题,这篇博客中就来介绍下相关的概念。 缓存的种类 L1:指令缓存、数据缓存,核独占 L2:数据指令通用,核独占 L3:核共享 这里以包含式 L3 为例: L3 包含 L1/L2 的所有数据 L3 的目录记录:这行在哪些核的 L1/L2 里 举例:Core 1 想读一个地址: 查 L3 目录 发现 Core 0 有 Modified 副本 通知 Core 0 写回 按照 L1 → L2 → L3 顺序访问,一个 miss 了就下一个,访问速度递减,大小递增。 缓存映射方式缓存映射方式主要有三种: 直接映射(1 路组相联) 组相联 全相联(缓存行数 = 路数) 下面的动画中详细解释: 👉 点击查看组相联缓存动画演示 缓存行置换算法常用的是 Tree PLRU(用二叉树近似 LRU)。为什么不用纯 LRU 呢?是因为硬件成本的问题: 存储缓存行状态需要额外的空间 N 路组相联需要的空间 = log₂(N!) × 组数 =...
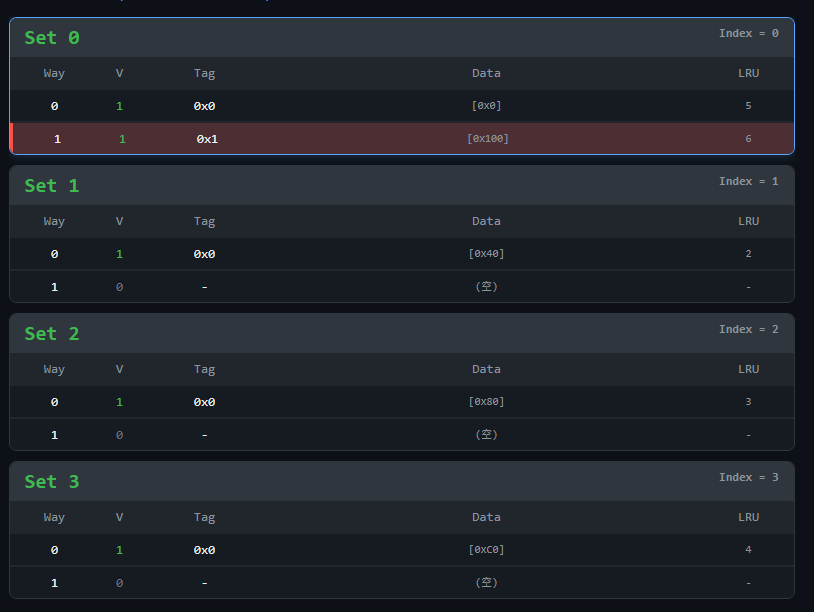
C++ new
C++ 中 new 是如何工作的呢? 创建对象数组示例以创建一个对象数组举例: 1234567891011121314#include <iostream>class Test {public: int value; Test(int v) : value(v) { std::cout << "ctor" << value << std::endl; } ~Test() { std::cout << "dtor" << value << std::endl; }};int main() { Test *arr = new Test[5]{1, 2, 3, 4, 5}; delete[] arr; return 0;} arr 拿到的地址是 0x000055555556b2b8,指向的是第一个对象。 内存布局 可以看到小端序存储的五个 value。...
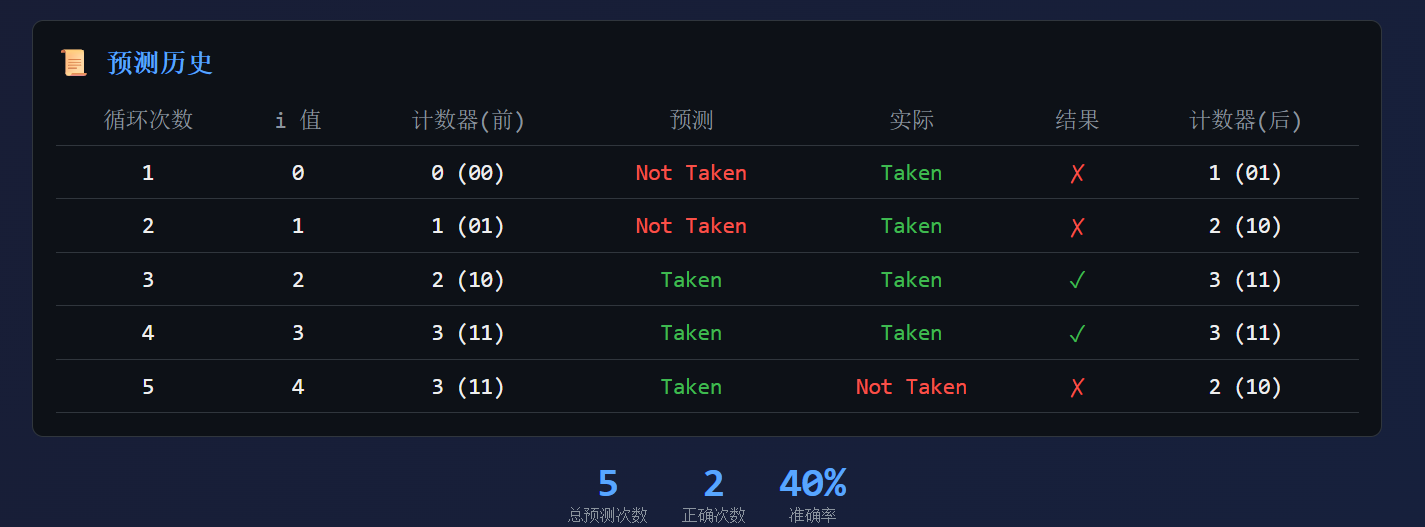
gem5分支预测──LocalBP
LocalBP 是 gem5 中最简单的分支预测算法,代码在 src/cpu/pred/2bit_local.cc 主要组件1. 计数器表 (localCtrs)一个数组,每个元素是一个 2-bit 饱和计数器(可配置)。默认 1024 个表项(可配置),每个表项对应一个或多个分支指令(可能存在 hash 冲突)。这里以默认举例。 2. 2-bit 饱和计数器 状态值 二进制 含义 预测结果 0 00 Strongly Not Taken 不跳转 1 01 Weakly Not Taken 不跳转 2 10 Weakly Taken 跳转 3 11 Strongly Taken 跳转 判断规则:看最高位 (MSB) MSB = 0 (值 0,1) → 预测不跳转 MSB = 1 (值 2,3) → 预测跳转 状态转换也很简单,跳转就 +1,没有跳转就 -1: 123456 +1 (taken) +1 (taken) +1 (taken)00 ───────────> 01 ───────────&g...