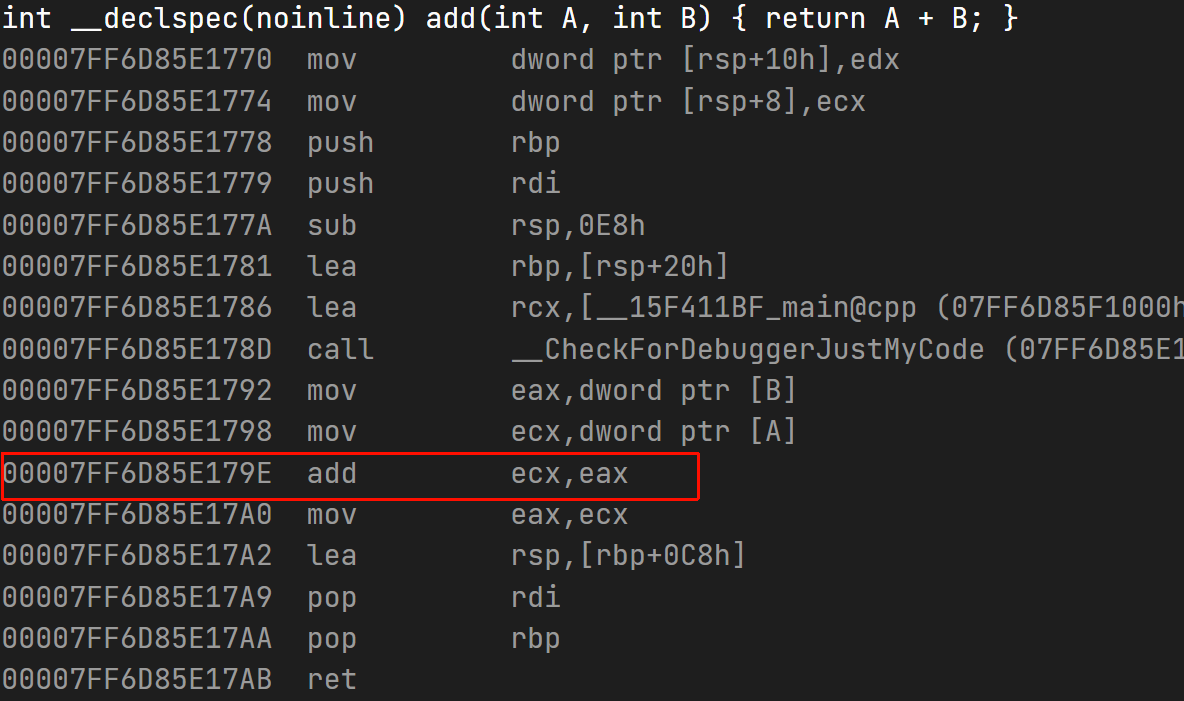
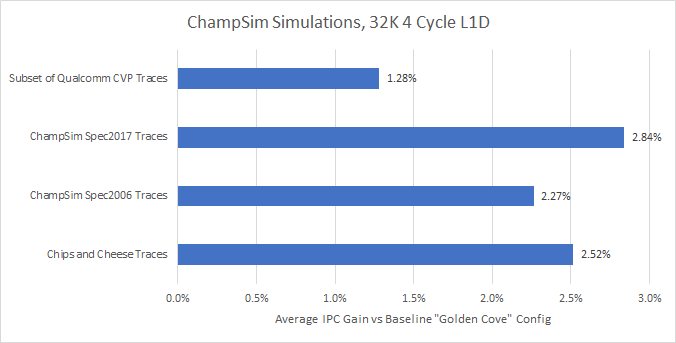
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
| Python 3.11.1 Trace BINARY_OP (add)
~181 ASM instructions
ceval.c:5544 // TARGET(BINARY_OP) { - 147 hits before stepping
00007FFDFD04F40F mov qword ptr [r11+38h],r14
00007FFDFD04F413 add r14,2
00007FFDFD04F417 jmp _PyEval_EvalFrameDefault+5872h (07FFDFD04F462h)
00007FFDFD04F462 mov rdi,qword ptr [r12-8]
00007FFDFD04F467 lea rax,[__ImageBase (07FFDFCE20000h)]
00007FFDFD04F46E mov rsi,qword ptr [r12-10h]
00007FFDFD04F473 sub r12,8
00007FFDFD04F477 mov rdx,rdi
00007FFDFD04F47A mov rcx,rsi
00007FFDFD04F47D call qword ptr [rax+r13*8+3E7A70h]
00007FFDFCF07380 mov qword ptr [rsp+8],rbx
00007FFDFCF07385 push rdi
00007FFDFCF07386 sub rsp,30h
00007FFDFCF0738A xor r8d,r8d
00007FFDFCF0738D mov rdi,rdx
00007FFDFCF07390 mov rbx,rcx
00007FFDFCF07393 call binary_op1 (07FFDFCF06C70h)
00007FFDFCF06C70 mov qword ptr [rsp+10h],rbp
00007FFDFCF06C75 mov qword ptr [rsp+18h],rsi
00007FFDFCF06C7A mov qword ptr [rsp+20h],rdi
00007FFDFCF06C7F push r14
00007FFDFCF06C81 sub rsp,20h
00007FFDFCF06C85 mov rsi,rdx
00007FFDFCF06C88 movsxd r9,r8d
00007FFDFCF06C8B mov rdx,qword ptr [rcx+8]
00007FFDFCF06C8F mov rbp,rcx
00007FFDFCF06C92 mov rdi,qword ptr [rdx+60h]
00007FFDFCF06C96 test rdi,rdi
00007FFDFCF06C99 je binary_op1+2Fh (07FFDFCF06C9Fh)
00007FFDFCF06C9B mov rdi,qword ptr [rdi+r9]
00007FFDFCF06C9F mov rcx,qword ptr [rsi+8]
00007FFDFCF06CA3 mov qword ptr [rsp+30h],rbx
00007FFDFCF06CA8 cmp rcx,rdx
00007FFDFCF06CAB je binary_op1+55h (07FFDFCF06CC5h)
00007FFDFCF06CC5 xor ebx,ebx
00007FFDFCF06CC7 lea r14,[_Py_NotImplementedStruct (07FFDFD2E6AF0h)]
00007FFDFCF06CCE test rdi,rdi
00007FFDFCF06CD1 je binary_op1+0ADh (07FFDFCF06D1Dh)
00007FFDFCF06CD3 test rbx,rbx
00007FFDFCF06CD6 je binary_op1+90h (07FFDFCF06D00h)
00007FFDFCF06D00 mov rdx,rsi
00007FFDFCF06D03 mov rcx,rbp
00007FFDFCF06D06 call rdi
00007FFDFCF60410 mov rax,qword ptr [rcx+8]
00007FFDFCF60414 test dword ptr [rax+0A8h],1000000h
00007FFDFCF6041E je long_add+24h (07FFDFCF60434h)
00007FFDFCF60420 mov rax,qword ptr [rdx+8]
00007FFDFCF60424 test dword ptr [rax+0A8h],1000000h
00007FFDFCF6042E jne _PyLong_Add (07FFDFCF60380h)
00007FFDFCF60380 sub rsp,28h
00007FFDFCF60384 mov r8,rdx
00007FFDFCF60387 mov rdx,qword ptr [rcx+10h]
00007FFDFCF6038B lea rax,[rdx+1]
00007FFDFCF6038F cmp rax,3
00007FFDFCF60393 jae _PyLong_Add+3Eh (07FFDFCF603BEh)
00007FFDFCF60395 mov r9,qword ptr [r8+10h]
00007FFDFCF60399 lea rax,[r9+1]
00007FFDFCF6039D cmp rax,3
00007FFDFCF603A1 jae _PyLong_Add+3Eh (07FFDFCF603BEh)
00007FFDFCF603A3 mov ecx,dword ptr [rcx+18h]
00007FFDFCF603A6 mov eax,dword ptr [r8+18h]
00007FFDFCF603AA imul rcx,rdx
00007FFDFCF603AE imul rax,r9
>>>>>>>>>>> 00007FFDFCF603B2 add rcx,rax ; <-- 真正的加法在这里!
00007FFDFCF603B5 add rsp,28h
00007FFDFCF603B9 jmp _PyLong_FromSTwoDigits (07FFDFCF5AF10h)
00007FFDFCF5AF10 push rdi
00007FFDFCF5AF12 sub rsp,20h
00007FFDFCF5AF16 lea rax,[rcx+5]
00007FFDFCF5AF1A mov rdi,rcx
00007FFDFCF5AF1D cmp rax,105h
00007FFDFCF5AF23 ja _PyLong_FromSTwoDigits+2Fh (07FFDFCF5AF3Fh)
00007FFDFCF5AF3F lea rax,[rcx+3FFFFFFFh]
00007FFDFCF5AF46 cmp rax,7FFFFFFFh
00007FFDFCF5AF4C jae _PyLong_FromSTwoDigits+48h (07FFDFCF5AF58h)
00007FFDFCF5AF4E add rsp,20h
00007FFDFCF5AF52 pop rdi
00007FFDFCF5AF53 jmp _PyLong_FromMedium (07FFDFCF5AE50h)
00007FFDFCF5AE50 mov qword ptr [rsp+10h],rbx
00007FFDFCF5AE55 push rsi
00007FFDFCF5AE56 sub rsp,20h
00007FFDFCF5AE5A movsxd rsi,ecx
00007FFDFCF5AE5D mov edx,20h
00007FFDFCF5AE62 mov rcx,qword ptr [_PyObject (07FFDFD3B8CA8h)]
00007FFDFCF5AE69 call qword ptr [_PyObject+8h (07FFDFD3B8CB0h)]
00007FFDFCF73E60 push rbx
00007FFDFCF73E62 sub rsp,20h
00007FFDFCF73E66 mov rbx,rdx
00007FFDFCF73E69 call pymalloc_alloc (07FFDFCF73C80h)
00007FFDFCF73C80 sub rsp,28h
00007FFDFCF73C84 lea rax,[rdx-1]
00007FFDFCF73C88 cmp rax,1FFh
00007FFDFCF73C8E jbe pymalloc_alloc+17h (07FFDFCF73C97h)
00007FFDFCF73C97 mov qword ptr [rsp+30h],rbx
00007FFDFCF73C9C mov qword ptr [rsp+38h],rsi
00007FFDFCF73CA1 mov qword ptr [rsp+40h],rdi
00007FFDFCF73CA6 lea edi,[rdx-1]
00007FFDFCF73CA9 shr edi,4
00007FFDFCF73CAC mov qword ptr [rsp+20h],r14
00007FFDFCF73CB1 lea r14,[__ImageBase (07FFDFCE20000h)]
00007FFDFCF73CB8 lea eax,[rdi+rdi]
00007FFDFCF73CBB lea rsi,[rax*8+4C7120h]
00007FFDFCF73CC3 mov rdx,qword ptr [rsi+r14]
00007FFDFCF73CC7 mov rcx,qword ptr [rdx+10h]
00007FFDFCF73CCB cmp rdx,rcx
00007FFDFCF73CCE je pymalloc_alloc+9Fh (07FFDFCF73D1Fh)
00007FFDFCF73CD0 mov r9,qword ptr [rdx+8]
00007FFDFCF73CD4 inc dword ptr [rdx]
00007FFDFCF73CD6 mov rax,qword ptr [r9]
00007FFDFCF73CD9 mov qword ptr [rdx+8],rax
00007FFDFCF73CDD test rax,rax
00007FFDFCF73CE0 jne pymalloc_alloc+1C1h (07FFDFCF73E41h)
00007FFDFCF73E41 mov r14,qword ptr [rsp+20h]
00007FFDFCF73E46 mov rax,r9
00007FFDFCF73E49 mov rdi,qword ptr [rsp+40h]
00007FFDFCF73E4E mov rsi,qword ptr [rsp+38h]
00007FFDFCF73E53 mov rbx,qword ptr [rsp+30h]
00007FFDFCF73E58 add rsp,28h
00007FFDFCF73E5C ret
00007FFDFCF73E6E test rax,rax
00007FFDFCF73E71 jne _PyObject_Malloc+46h (07FFDFCF73EA6h)
00007FFDFCF73EA6 add rsp,20h
00007FFDFCF73EAA pop rbx
00007FFDFCF73EAB ret
00007FFDFCF5AE6F mov rbx,rax
00007FFDFCF5AE72 test rax,rax
00007FFDFCF5AE75 jne _PyLong_FromMedium+4Ah (07FFDFCF5AE9Ah)
00007FFDFCF5AE9A mov qword ptr [rsp+30h],rdi
00007FFDFCF5AE9F mov eax,esi
00007FFDFCF5AEA1 cdq
00007FFDFCF5AEA2 mov rcx,rsi
00007FFDFCF5AEA5 sar rcx,3Fh
00007FFDFCF5AEA9 mov edi,eax
00007FFDFCF5AEAB and rcx,0FFFFFFFFFFFFFFFEh
00007FFDFCF5AEAF lea rax,[PyLong_Type (07FFDFD2E52E0h)]
00007FFDFCF5AEB6 xor edi,edx
00007FFDFCF5AEB8 mov qword ptr [rbx+8],rax
00007FFDFCF5AEBC inc rcx
00007FFDFCF5AEBF sub edi,edx
00007FFDFCF5AEC1 mov qword ptr [rbx+10h],rcx
00007FFDFCF5AEC5 test dword ptr [PyLong_Type+0A8h (07FFDFD2E5388h)],200h
00007FFDFCF5AECF je _PyLong_FromMedium+88h (07FFDFCF5AED8h)
00007FFDFCF5AED8 cmp dword ptr [_Py_tracemalloc_config+4h (07FFDFD2E7324h)],0
00007FFDFCF5AEDF je _PyLong_FromMedium+99h (07FFDFCF5AEE9h)
00007FFDFCF5AEE9 mov dword ptr [rbx+18h],edi
00007FFDFCF5AEEC mov rax,rbx
00007FFDFCF5AEEF mov rdi,qword ptr [rsp+30h]
00007FFDFCF5AEF4 mov qword ptr [rbx],1
00007FFDFCF5AEFB mov rbx,qword ptr [rsp+38h]
00007FFDFCF5AF00 add rsp,20h
00007FFDFCF5AF04 pop rsi
00007FFDFCF5AF05 ret
00007FFDFCF06D08 mov rcx,rax
00007FFDFCF06D0B cmp rax,r14
00007FFDFCF06D0E jne binary_op1+0D9h (07FFDFCF06D49h)
00007FFDFCF06D49 mov rbx,qword ptr [rsp+30h]
00007FFDFCF06D4E mov rbp,qword ptr [rsp+38h]
00007FFDFCF06D53 mov rsi,qword ptr [rsp+40h]
00007FFDFCF06D58 mov rdi,qword ptr [rsp+48h]
00007FFDFCF06D5D add rsp,20h
00007FFDFCF06D61 pop r14
00007FFDFCF06D63 ret
00007FFDFCF07398 mov rcx,rax
00007FFDFCF0739B lea rax,[_Py_NotImplementedStruct (07FFDFD2E6AF0h)]
00007FFDFCF073A2 cmp rcx,rax
00007FFDFCF073A5 je PyNumber_Add+35h (07FFDFCF073B5h)
00007FFDFCF073A7 mov rax,rcx
00007FFDFCF073AA mov rbx,qword ptr [rsp+40h]
00007FFDFCF073AF add rsp,30h
00007FFDFCF073B3 pop rdi
00007FFDFCF073B4 ret
00007FFDFD04F485 sub qword ptr [rsi],1
00007FFDFD04F489 mov r15,rax
00007FFDFD04F48C jne _PyEval_EvalFrameDefault+58AFh (07FFDFD04F49Fh)
00007FFDFD04F49F sub qword ptr [rdi],1
00007FFDFD04F4A3 jne _PyEval_EvalFrameDefault+58C6h (07FFDFD04F4B6h)
00007FFDFD04F4B6 mov qword ptr [r12-8],r15
00007FFDFD04F4BB test r15,r15
00007FFDFD04F4BE mov r15,qword ptr [rsp+30h]
00007FFDFD04F4C3 je _PyEval_EvalFrameDefault+161h (07FFDFD049D51h)
00007FFDFD04F4C9 add r14,2
00007FFDFD04F4CD jmp _PyEval_EvalFrameDefault+59FCh (07FFDFD04F5ECh)
|