Break the Serial Dependency Chain
本文为学习 Computer Enhance - Instructions Per Clock 的整理。
前情回顾
上一篇博客中,我们通过循环展开进行了示例代码的优化,也遇到了串行依赖链的问题。这篇博客就来进一步说明。
之前的优化代码:
1 | u32 Unroll4Scalar(u32 Count, u32 *Input) |
什么是串行依赖链?
每个 add 的第一个操作数始终是同一个累加值 Sum。它既是 add 的源,也是其目的地。
这部分代码是一个 串行依赖链:整个求和过程中的每一次加法,都依赖于前一次加法的结果,一路追溯到循环的第一次迭代。
当 CPU 看到这样一条链时,它没有任何办法加速——必须按顺序执行。它必须等前一条加法完成,才能开始下一条。我们写出来的循环体里,CPU 唯一能并行做的只有循环本身的维护工作。它可以一边维护循环,一边执行加法,但 永远无法把加法本身并行化。
打破依赖链
加法满足 结合律 和 交换律——我们可以随意重新排列。我们可以调换加法的顺序,可以先把数两两相加再把结果相加,也可以把偶数下标和奇数下标分别求和,最后再合并。
因此,我们完全可以通过修改代码,增加临时变量,打破这个串行依赖链。
双累加器 (DualScalar)
1 | u32 DualScalar(u32 Count, u32 *Input) |
四累加器 (QuadScalar)
1 | u32 QuadScalar(u32 Count, u32 *Input) |
进一步优化:指针遍历 (QuadScalarPtr)
可以进一步优化循环结构,去除地址计算,改为固定偏移:
1 | u32 QuadScalarPtr(u32 Count, u32 *Input) |
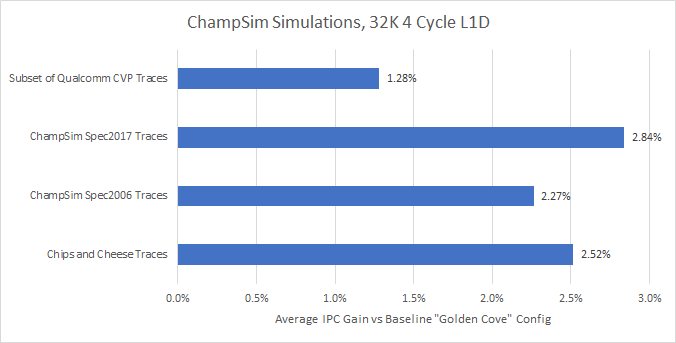
性能测试结果
| 函数 | 周期数 | adds/cycle |
|---|---|---|
| DualScalar | 2336 | 1.753 |
| QuadScalar | 1916 | 2.138 |
| QuadScalarPtr | 950 | 4.312 |
回顾:编译器的优化
在上篇博客中,我们说了 Unroll4Scalar 被额外优化了。这个额外优化就是 打破依赖链,编译器生成的代码大致如下:
1 | u32 Unroll4Scalar(u32 Count, u32 *Input) |
编译器打破了对 Sum 的依赖。在之前的代码中,依赖不只是一个循环内的,多个循环之间也存在依赖。打破后,下一循环可以提前开始计算 tmp。
这就是性能大幅提升的原因。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2026-01-13
Unrolling a Loop
本文为学习 Computer Enhance - Instructions Per Clock 的整理。 问题引入有如下代码: 1234567891011typedef unsigned int u32;u32 SingleScalar(u32 Count, u32 *Input){ u32 Sum = 0; for (u32 Index = 0; Index < Count; ++Index) { Sum += Input[Index]; } return Sum;} 每颗 CPU 在理论上每个时钟周期都能执行一定数量的指令,而我们的工作负载越接近这个数量,就越能发挥这颗 CPU 的全部潜力。 上述代码中,可以认为 加法是工作负载,而 循环是一种”浪费”。下面是上述代码生成的汇编: 1234567891011121314151617SingleScalar: test ecx, ecx ; if (Count == 0) je ....

2026-01-13
Single Instruction, Multiple Data (SIMD)
本文为学习 Computer Enhance - Single Instruction, Multiple Data 的整理。 回顾与引入在前一篇博客中,我们通过 打破指令依赖链,让 CPU 可以并行执行 add 操作,从而提升了性能。 在这篇博客中,我们回到第一种优化方式:通过使用 SIMD 指令来减少指令总数。 SIMD 全称 Single Instruction, Multiple Data(单指令多数据),它的意思正如字面所示:CPU 用一条指令同时处理多份数据。 SIMD 基础常见的 SIMD 指令集包括 SSE、AVX 和 AVX-512。指令宽度依次加倍,分别是 128 bit、256 bit 和 512 bit。宽度决定了一条指令一次性可以计算的数据长度。 现在的家用电脑一般都支持到 AVX2。下图是我的 CPU 数据,可以看到对 SIMD 指令集的支持情况: 寄存器对应关系SIMD 指令会使用专用的寄存器做计算: SSE (128位): 使用 XMM0 ~ XMM15 AVX (256位): 使用 YMM0 ~ YMM15 XMM0 是 YMM0 的低 1...

2026-01-12
Waste
本文为学习 Computer Enhance - Waste 的整理。 核心观点提升程序性能只有两条路: 减少要求 CPU 执行的指令总数 调整这些指令,让它们更高效地穿过 CPU 除此之外,别无他法:要么减少数量,要么加快速度。 CPU 正在执行的指令中,存在大量指令,它们所做的事情,与实际程序逻辑毫无关系。 案例:计算 A + B运行在两个较为极端的环境下: C 语言:编译为原生机器码,运行在 CPU 上 Python:编译为字节码,运行在 CPython 虚拟机上(没有 JIT) C 语言实现测试代码: 12345678910int __declspec(noinline) add(int A, int B){ return A + B;}#pragma optimize("", off)int main(int ArgCount, char **Args){ return add(1234, 5678);} 可以看到为了实现 A + B,只使用了 一条 ADD 指令。 Python ...